Creating My Website
My initial build of this site was a Preact site that was statically hosted in an S3 bucket and served via Cloudfront. I used Vite as the build tool and had Github actions setup to automatically deploy to S3 and clear the cloudfront cache.
This was a reasonably good setup for a static site with a small amount of content, the pages are edge cached and Preact is quite small so loading times were good.
However, at around the time I started making this site I also started using Remix on a project at work. I immediately fell in love with remix and decided it would be a good idea to rebuild my site in remix while it was still relatively small.
Why Remix?
MDX Support
My main plan for this website is for it to be a place where I can share my projects, and write about developer related things that I am interested in. In my initial build I created my own static API generator which would read the metadata of markdown files and generate a static API for the site (the code for this can be found here). While I did quite like this solution at the time I did feel a bit like I was re-inventing the wheel.
Remix has built in support for MDX so I can write these blog posts using mostly markdown with javascript elements thrown in when I need to. In the future I plan on adding pagination and tag searching but for now I am keeping it simple as I only have a few posts.
Efficient Caching
One of the best things about remix is that is designed with the modern web standards in mind, this means that effectively utilizing caching
is super easy. I have remix running in a AWS Lambda function that is sat behind
Cloudfront. Remix gives you the ability to have fine grained control over cache headers, you can set
default headers in the entry.server.tsx file that will always be applied unless headers are specified. For example here is how I have set
the cache headers on this site:
const cacheControl = responseHeaders.get('Cache-Control');
if (!cacheControl) {
responseHeaders.set(
'Cache-Control',
'public, max-age=86400, s-maxage=2628000, stale-while-revalidate=31560000'
);
}
This means that even though this site is running in a lambda, that lambda code is almost never running. The lambda will only run on the first request, after that point the cached page will always be served directly from cloudfront.
The stale-while-revalidate header ensures that no users have to wait for a page to load from lambda, instead the first user to hit the site when the cache has runout will be served a stale page. Simultaneously to this cloudfront will be requesting the lambda for the updated content, so all users (except the first ever) get a cached page. This video explains this concept super well.
This way of doing things is really cool in my opinion, you get all the benefits of server side rendering with all the benefits of a static site.
Javascriptless rendering
While Preact is an extremely performant and small library, Remix has the advantage of being server side rendered. This means that each page is functional and styled without executing any javascript. This means that users could use this site without executing any front end code, the same cannot be said for a Preact based site.
As a Preact site grows in size and scope the bundle size will increase meaning that the site will take longer to load. The same cannot be said for Remix, each page is rendered in isolation and only loads the javascript, css and html it needs.
More control
Remix gives you a lot of control over things like headers, link tags and meta tags. Often these things are a lot harder to take control of in a progressive web app as each page is technically loading the same html file, meaning that the tags have to be added after first render.
Having each page be a server side rendered html file means that SEO is improved as bots can immediately read header information without having to execute any javascript.
It's cool
While there are a lot of advantages of Remix it's also just really fun to use. I like the fact it's focused on making use of web standards rather than re-inventing the wheel. I like that it's focused on performance without having to sacrifice. I like that you don't have to worry about state management all the time. It's just really cool!
Storybook
Storybook is a fantastic tool for component driven development. Storybook allows you to create stories to work on and test your components in isolation. When doing a component driven approach to development its quite easy to create components that have side effects or rely on other components to work properly. Utilizing storybook to create the components in a site helps avoid this by forcing you to make components work on their own.
Storybook also acts as a good reference for other developers that work on a project to see the ways a component can/should be used. Although this site is quite small with relatively few components, I have still used storybook to build it as I believe its best practice.
Tailwind
Tailwind is a css utility framework that uses class composition to style a site. Tailwind is really great because it gets out of your way. Rather than having to constantly worry about semantic class naming and structure, you can just get straight to styling. To some Tailwind is contreversial because it moves away from the traditional semantic class names 'best practice'. I think that This blog post by the creator of tailwind justifies quite well why the tailwind approach is actually better.
Pulumi
As previously sated in this blog post I have used AWS as the infrastructure for this site, to manage this infrastructure I have used the Infrastructure as Code tool Pulumi.
I think Pulumi is a fantastic tool as it allows you to setup your infrastructure using javascript, I prefer this over other approaches like Terraform as dealing with a domain specific language can often be restrictive.
Here is a diagram showing what the infrastructure of this site looks like:
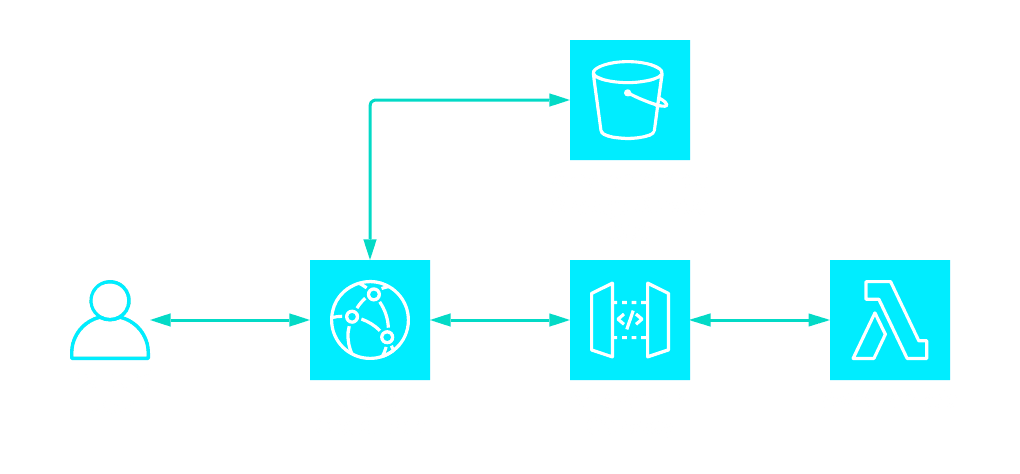
When a user requests a page, cloudfront will first check if it has a cached version of that page, if it does it will serve that page, if not it will make a request to the lambda via Amazon API Gateway. When a page is served to the user, that page will also contain some links to static assets e.g css files, js files and images. These static assets are stored in the S3 bucket and served in the same way, cloudfront will either served a cached version of the asset or request for the asset from S3.
The future
I plan on continually working on and improving this site in my free time as well as adding new blog posts. If you found this interesting and would like to see the source code of this site it is all publicly available on my Github.